How did Caesar get through the Ides of March? How will you?
If your answer to that question is “Caffeine Consumption,” then you’re not alone. One source estimates that 80-90% of adults in North America consume caffeine habitually. To draw attention to the prevalence of caffeine use in America, March has been designated as National Caffeine Awareness Month. And here on the Mystery Map team, we always want to promote awareness of where you can find a cup of coffee nearby … which brings me to the identity of the Mystery Variable.
The Answer Is:
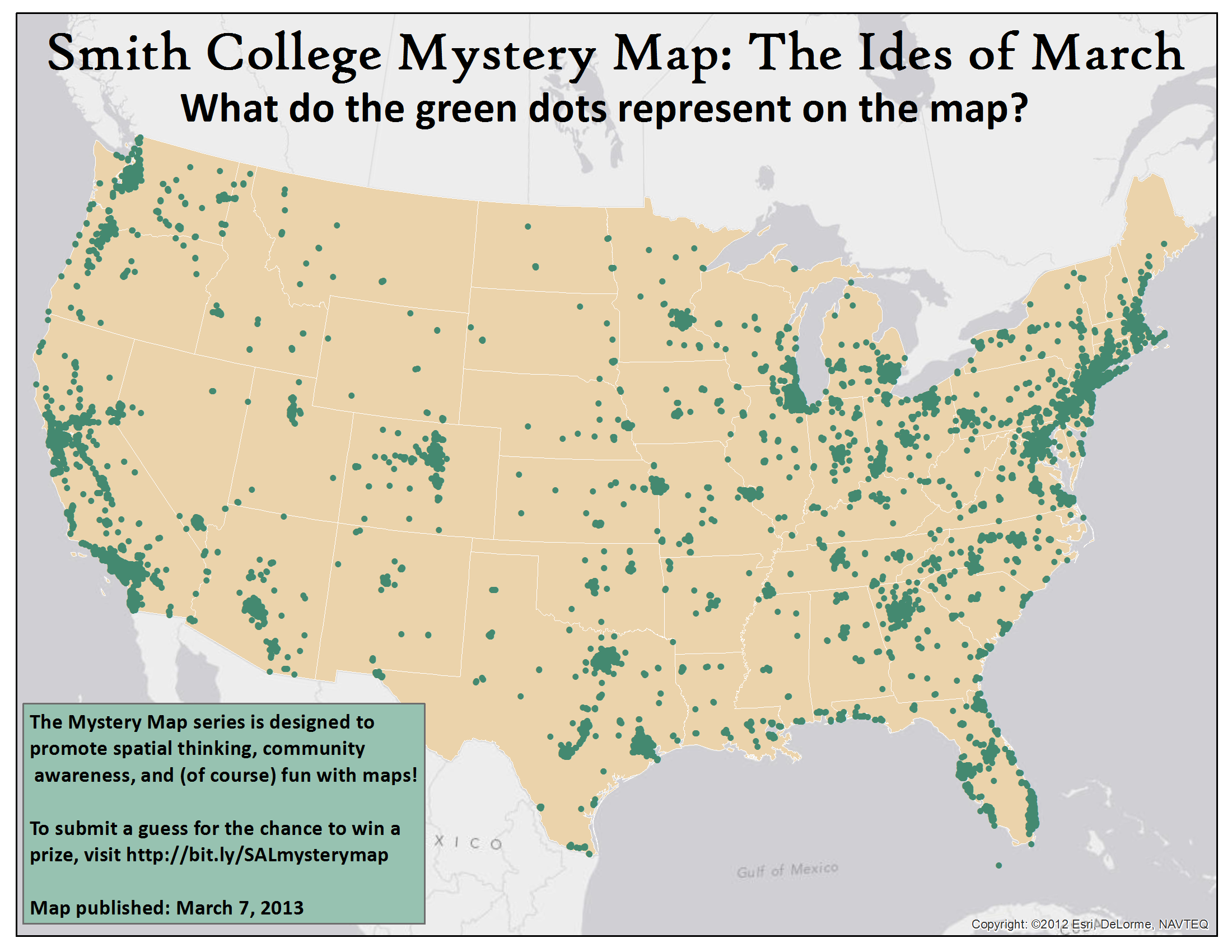
Click to enlarge the map
The green dots show the location of Starbucks Coffee Shops in the United States. There are approximately 13,100 Starbucks locations in the US (though the number is constantly slightly in flux as locations close and open every week).
California boasts the most of the ubiquitous coffee house with 2,947 Starbucks, while Vermont shows its independence from chains (or possibly its preference for Diet Coke?) with only 4 Starbucks, the lowest number nationwide. Here in Northampton, there are two– do you know where both of them are located? (Hint: Don’t forget that in addition to standalone storefronts, there are often Starbucks counters in malls, supermarkets, airports, and other large commercial buildings.)
The Winner Is:
Congratulations to Arcadia Kratkiewicz, who was the first of two contestants who solved the map this month! Great job, Arcadia!
Making of the Mystery Map:
Putting the Starbucks locations on the map was fairly straightforward: we found a spreadsheet with a record for every Starbucks store, along with the map coordinates expressed as latitude and longitude, on the Socrata Open Data website (follow the link to explore the raw data in map or spreadsheet form!). Using a built-in tool in ArcGIS, we were able to transform the latitude and longitude “ordered pairs” from the spreadsheet into points on the map. Violá! The main map (of the green dots shown over a map of the contiguous states) was finished.
However, we want to challenge you to think a little deeper about the choices inherent in making maps. The case of mapping Starbucks points on the main “green dots” map sheds light on a common cartographic conundrum that mapmakers and other GIS users often face. With over 13,000 tiny green points on the map, how clearly does this map help users understand the distribution of Startbucks locations in the United States? On one hand, this map indicates that there are large clusters of “green dots” in major urban areas, and allows map-readers to understand general trends in where the “green dots” are located (urban vs. rural, coasts vs. midwest, etc). On the other hand, there are 194 Starbucks locations on the island of Manhattan alone, but at the scale of this map (with the dots overlapping in dense areas), Manhattan could as easily contain 10 dots as nearly 200– the user truly can’t tell the difference between the number of dots in the large cluster around New York City and the number of dots in the large cluster around Atlanta, Georgia (in reality, New York City has about 5 times more Starbucks).
With that in mind, look again at the four alternate views of the “green dots” (which you now know to be Starbucks Locations):
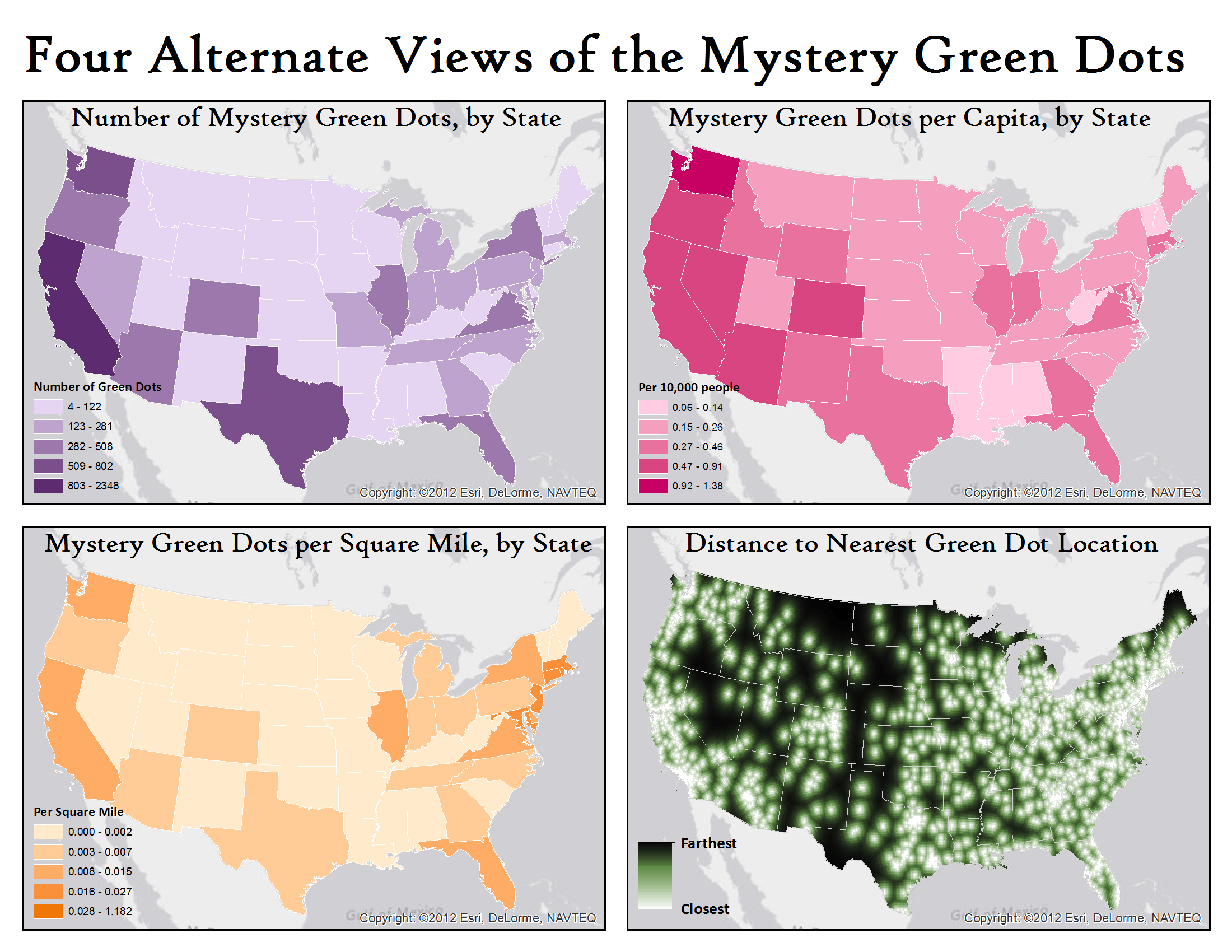
Click to enlarge the maps
The distance map in the lower right corner is modeled on the iconic map of the distance to the nearest McDonalds, and is mainly included as a different way to visualize the point distribution. However, the other three maps are a particular type of map called a choropleth map, where areas are shaded accorded to a statistical value shown on the map. Here, we have three choropleth maps: one showing the raw number of Starbucks in each state (purple), one where the number of Starbucks is normalized by population (pink), and one where the number of Starbucks is normalized by area (orange).
Choropleth maps are useful because they aggregate data in a way that lets map users make comparisons. However, they can also be misleading. Consider this [completely fictional] example: I am making a map of support for the Shamrock Party in the United States. In Iowa last year, 500 people voted Shamrock; in California, 500 people also voted for the Shamrock candidate. Does this mean that support for the Shamrock Party is equal in the two states? In this case, the map-maker would want to normalize the data to account for the differing populations between the two states. Mapping allegiance to the Shamrock party divided by the state population would reveal that a much greater percentage of Iowans support the Shamrockers. Similarly, in some cases, it might make sense to normalize by area: a choropleth map showing the state-by-state acreage of land earmarked for conservation should be shown as a percentage of the overall area of the state.
With this is mind, what choropleth map of the number of Starbucks make the most sense? Mapping the raw number of stores? Or normalizing that value by area? Or population? There are arguments to be made on all three sides. Thinking about it has made me a little tired… quick, someone get me a cup of coffee!