This lab introduces you to a form of lightweight process called POSIX threads. (POSIX is a standard that describes how Unix variants like Linux operate, and portions of it have been adopted for use with other operating systems. Thus the study of POSIX threads is widely applicable.) The material presented here complements what we did in the last lab, which looked at creation of new heavyweight processes.
Since threads can share data (i.e., static global variables) with each other, they tend to cooperate more closely than child processes created using fork. However, with closer communication comes greater potential for detrimental interactions between threads. To help manage these interactions, a number of synchronization mechanisms are available, including some that we have studied such as semaphores, and other variants on the same theme such as mutex, conditions, and wait queues. These are described in more detail below, for those interested in learning more.
The questions in the lab below are intended for your enrichment; you are not required to answer them. Instead, your task for this lab will be to build a program that implements a producer/consumer model with bounded buffer. Start with the framework provided. You will need to add calls to create the producer and consumer threads and to wait for them to terminate. At this point, the program should function but will exhibit race conditions due to interactions between the two threads. (What evidence do you see of these race conditions?) As the final part of your task for this lab, apply one of the thread synchronization mechanisms discussed below to achieve mutual exclusion of the critical sections of the two threads.
This lab can be completed on any system with POSIX threads -- you don't need root access to use the POSIX thread library.
Contents
Questions: Q1, Q2, Q3, Q4, Q5, Q6, Q7, Q8, Q9, Q10, Q11, Q12, Q13, Q14.
Getting started with threads
Threads are parallel, independent execution units which share the same code and data segments. A process is a collection of one or more execution threads. Processes characterized by only one thread of execution are called single-threaded. On the other hand, a multi-threaded process has multiple threads of execution (see picture below).
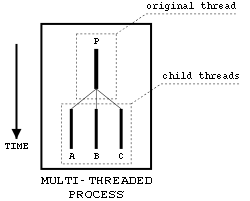
A new process always starts with a single thread, the
parent or original thread (P in the figure
above). During its execution, a thread can generate other
threads of execution using the
pthread_create() function. In the figure
above, the A, B and C
threads originated from the P thread.
The behaviour of pthread_create() is similar to
the fork() routine, described in the lab on processes, which allows new
processes to be forked
from an original process. However, unlike a child
process originated from fork(), a newly created
thread shares its global variables (data segment) with all of
the other threads belonging to the same process. This means that
changes made by one thread will be immediately visible to its
sibling threads, and race conditions resulting from simultaneous
operations on a variable by two different threads are a distinct
possibility.
 |
Q1. In the last paragraph we explained the similarities
between the fork() and
pthread_create()
functions. fork() splits the current process
into two child processes, while
pthread_create() splits the current thread
into two threads of execution. Can you guess which
function is faster? Explain your answer. |
pthread_create() is defined in
/usr/include/pthread.h (notice that it is not
part of the Linux kernel):
int pthread_create(pthread_t *thread_id, pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);
On success, a thread is created and its identifier stored in
the variable pointed by thread_id. The thread
starts executing from the start_routine
function. Notice the format of the
start_routine: the function must return a
void * pointer, and take a void *
as argument. See the example below.
If you wish to have the parent thread wait for its children
to finish, it should execute a pthread_join() function,
which suspends the parent thread until the child finishes with
pthread_exit().
int main(void)
{
pthread_t id;
pthread_create(&id, NULL, &my_thread, NULL); /* create thread */
/* ORIGINAL THREAD */
/* do something... */
pthread_join(id,NULL);
/* do something else... */
pthread_exit(NULL);
}
static void *my_thread(void *p)
{
/* NEW THREAD */
/* do something else... */
pthread_exit(NULL);
}
After the call to pthread_create(), the
main() and my_thread() functions
will run concurrently, each located on a different thread of
the same process.
Here, once again, the behaviour of
pthread_create() differs from
fork(). While fork() begins
execution of the new process exactly from its calling point,
pthread_create() begins execution of a new
thread from the function passed as the
start_routine parameter.
NOTE: On some systems, you may need to
compile programs with the pthread library in order
to use pthread_join(). Try the following if you get
error messages from the linker complaining that the pthread
functions have not been defined:
g++ my_thread_program.cpp -lpthread
Now consider another example similar to the one above:
static int main_lock = 1;
int main(void)
{
pthread_t id;
pthread_create(&id, NULL, &my_thread, NULL); /* create thread */
while(main_lock); /* busy loop */
/* PART A */
pthread_exit(NULL);
}
static void *my_thread(void *p)
{
/* PART B (critical) */
main_lock = 0;
/* PART C */
pthread_exit(NULL);
}
Two threads are created in the same way we saw in the previous
example. However, in this case we introduce a global
variable, main_lock. The main()
thread waits for this variable to become zero before entering
part A of its code. The second thread,
my_thread(), sets this lock to zero at some point
during its execution.
The example above shows a very primitive way to
synchronize threads. This code works because threads of
the same process share the same data segment, and therefore
the same global variables. A modification to
main_lock by one thread is also visible to the
other thread.
|
Q2. In the last example, what would have happened if the
threads didn't share the same data segment (such as with
fork())? |
|
Q3. List some examples of applications in which threads might be useful. |
Passing arguments to threads
It is possible to pass arguments to new threads through the
arg parameter of
pthread_create(). For example:
int main(void)
{
int element;
...
pthread_create(&id, NULL, &my_thread, &element);
...
pthread_exit(NULL);
}
static void *my_thread(void *p)
{
int arg = *p; /* retrieve argument */
printf("The argument passed to the thread is %d\n", arg);
pthread_exit(NULL);
}
Notice that we can only pass pointers through
pthread_create(). This limitation introduces a
problem: it is possible that the argument passed to a new
thread is modified by the original thread before the new
thread can actually retrieve it. Consider the example below:
int main(void)
{
int element;
...
element = 5;
pthread_create(&id, NULL, &my_thread, &element);
element = 3;
...
pthread_exit(NULL);
}
static void *my_thread(void *p)
{
int arg = *p; /* retrieve argument */
printf("The argument passed to the thread is %d\n", arg);
pthread_exit(NULL);
}
We cannot be sure which value of element will
be read by the new thread, 5 or 3. This is because we do not know the
order in which the threads are executed in a multiprogramming
environment.
|
Q4. Provide a solution for the "element"
problem in the last example. |
|
Q5. What is wrong with the following code?
Provide a correct alternative to the code above.
|
Synchronization between threads
Earlier in this document, we implemented a very primitive
synchronization method between two threads (see here). The implementation was making use
of a busy loop based on the global variable
main_lock. However, as the complexity and
number of threads of a process increase, ad hoc methods like
this become very impractical. For one thing, it can become difficult
to keep track of all the shared variables. For another, busy waiting
is very inefficient because the CPU spends all its time doing nothing but
wait for another thread -- which cannot run at the same time!
Fortunately, POSIX threads implement very powerful and inexpensive methods of synchronization between threads using mutex and conditions. We will describe some of these methods in the following paragraphs.
Spin locks
The simplest form of synchronization in the kernel are
spin-locks. Spin-locks cause the kernel to spin indefinitely
in a busy loop until some kind of resource
(represented by the lock) becomes available. One of the
functions that implements this behaviour is
spin_lock(), defined in include/asm/spinlock.h,
line 130:
static inline void spin_lock(spinlock_t *lock)
The function generates the following (simplified) assembly code:
1: lock; decb my_lock
jns 3f
2: cmpb $0, my_lock
jle 2b
jmp 1b
3:
The execution of the current kernel control path depends on
the my_lock variable. If my_lock is greater than
zero at the time spin_lock() is called, the
kernel will continue its normal execution. However, if
my_lock is less or equal to zero, the kernel will wait
in a busy loop until the lock becomes positive again.
The labels 1, 2 and 3 represent different phases of the
function. In part 1, my_lock is decremented
atomically. The lock instruction before
decb assures that on a multi-processor system
only one processor at the time can access the memory location
referred by my_lock. The jns (Jump If Not
Sign) instruction immediately next will then transfer code
execution to part 3 if the new value of my_lock is
greater or equal to zero, allowing the kernel to continue its
current path. On the other hand, if the new value of
my_lock is negative, the kernel will keep spinning in
part 2 until the lock becomes positive. At this point
execution is transferred to part 1 once again.
The function to release the lock, spin_unlock(),
is straightforward:
xchgb unlocked_value, my_lock
The code above sets the value of my_lock back to the
unlocked state, 1. unlocked_value is just a char
variable containing the value 1. xchg executes an
atomic exchange of values between the
unlocked_value and my_lock variables. The
lock instruction is not needed because it is
buil-in in xchg.
Several variants of spin_lock() and
spin_unlock() exist. For instance, a more
sophisticated spinlock is the read/write spin lock, which
allows several readers to enter simultaneously a critical
region of code. However, only one writer at the time is
allowed in the critical section. The functions that implement
this kind of spinlock are read_lock(),
write_lock(), and their unlock partners.
Spin-locks can be efficient if the contention between threads is expected to be limited and brief. On machines with multiple processors, spin-locks are often more convenient than other methods which must synchronize between independent processors. However, on computers with a single CPU, spin-locks are generally deprecated, and other techniques are used insted, such as semaphores and wait queues (described later).
|
Q6. What is the great disadvantage of using spin-locks? |
|
Q7. Suppose the assembly code for the
spin_lock() function is changed as shown
below. Will this new version still work? Explain.
|
|
Q8. What happens if a lock is initialized to 2 instead of 1? |
Mutex
A mutex is a mutual exclusion device, and is useful for protecting shared data structures from concurrent modifications, and implementing critical sections and monitors.
A mutex has two possible states: unlocked (not owned by any thread), and locked (owned by one thread). A mutex can never be owned by two different threads simultaneously. A thread attempting to lock a mutex that is already locked by another thread is suspended until the owning thread unlocks the mutex first.
A mutex is declared as pthread_mutex_t
data type.
Some of the POSIX functions that operate on a mutex are described below. Detailed information about each of these functions can be found in their manual pages.
pthread_mutex_init(mutex, attr), initializes a mutex variable.pthread_mutex_lock(mutex), tries to lock a mutex. On success, the mutex is locked and the thread continues its execution. On failure, the thread is suspended until the lock is released.pthread_mutex_unlock(mutex), unlocks a mutex and wakes up a suspended process (if any) waiting on the same mutex.pthread_mutex_destroy(mutex), destroys a mutex object.
In the following example we show two threads accessing the same global variables. These variables are protected by a mutex.
#include <pthread.h>
#define MAX_BUFFER 1000
int buffer[MAX_BUFFER];
int count = 0;
pthread_mutex_t mutex; /* mutex */
void *my_thread(void*);
int main(void)
{
pthread_t id;
pthread_mutex_init(&mutex, NULL); /* init mutex, default attributes */
pthread_create(&id, NULL, &my_thread, NULL);
while(count < MAX_BUFFER) {
pthread_mutex_lock(&mutex);/* enter critical region */
if (count < MAX_BUFFER) {
buffer[count] = count;
count++;
}
pthread_mutex_unlock(&mutex); /* exit critical region */
}
pthread_exit(NULL);
}
void *my_thread(void *p)
{
while(count < MAX_BUFFER) {
pthread_mutex_lock(&mutex);
if (count < MAX_BUFFER) {
buffer[count] = count;
count++;
}
pthread_mutex_unlock(&mutex);
}
pthread_exit(NULL);
}
|
Q11. Run the code above several times with the mutex
protection and without protection. At the end of the
program print the value of count and the
contents of the array. What difference do you observe
between the protected version of the program and the
unprotected one? |
Semaphores
Semaphores are a smarter form of synchronization than spin-locks for most applications. Instead of wasting CPU time in busy loops, semaphore functions can put processes to sleep until a given resource becomes available. While a process is sleeping, the CPU can execute other tasks, therefore making the best use of its time and increasing the system's global level of multiprogramming.
Semaphores are defined in include/asm/semaphore.h:
struct semaphore {
atomic_t count;
int sleepers;
wait_queue_head_t wait;
};
The count field indicates the number of simultaneous process
allowed to pass the semaphore at one time. A value of
1 allows only one process into the critical section at any time.
The functions that operate on semaphore are the following:
down(sem)anddown_interruptible(sem). If the semaphoresemis locked, meaning that count is zero (the maximum number of allowed functions have already entered the region protected by the semaphore), these functions put the current process to sleep until the semaphore is unlocked by theup()function. A process put to sleep usingdown_interruptible()can also be woken up by signals (see Processes and Process Scheduling: Sending signals to processes). If the semaphore is unlocked, the process continues its normal execution, with count decreased by one.up(sem), releases (unlocks) a semaphore. This action wakes up one process in the semaphore's waiting queue, if any processes are waiting. Otherwise it raises the count by one.
down_interruptible() is almost always preferred
to down(). The latter should be used with care
and only in some special cases.
One important feature of semaphore functions is that only one process is woken up when a semaphore is released. This differs from sleeping queues (described later), which awake all of the processes sleeping on a given queue.
Device drivers make use of semaphores and waiting queues all the time. Suppose a certain process issues a read from a device, such as a DVD drive. The drive's motor will take a few seconds to reach the optimal spin velocity and seek to the right position on disk. Meanwhile, the process that issued the read has to wait. The device driver in charge of the DVD player could implement this waiting as a busy loop, testing the device for a ready status at every loop iteration. However, this kind of waiting would waste a terrible amount of CPU time. A better solution is to put the process to sleep using semaphores or sleeping queues, until the DVD drive notifies (via interrupts) the processor that it is ready to accept commands.
The following example shows the design of a simple device
driver that uses semaphores. The driver creates the device
/dev/mutex. The first process reading from this
device will acquire a lock that will cause other read attempts
from any process to sleep. The lock is released when the
process that owns it closes the device.
struct semaphore sem;
/* Module Initialization */
static int __init dev_init(void)
{
...
dev_handle = devfs_register
(
...
"mutex", /* create /dev/mutex */
...
S_IFCHR | S_IRWXO | S_IRWXG | S_IRWXU, /* permissions, everybody RWX */
...
);
...
/* initialize semaphore */
sema_init(&sem, 1); /* one process per critical section */
return(0);
} /* dev_init() */
/* Read from device */
static ssize_t dev_read(struct file *filp, char *buf, size_t count, loff_t *offp)
{
if (down_interruptible(&sem))
return(-EINTR); /* sleeping has been interrupted by a signal */
return(count);
} /* dev_read() */
/* Close the device */
static int dev_release(struct inode *inode, struct file *filp)
{
up(&sem);
return(0);
}
Notice that the sempahore sem needs to be
initialized before it is used. Initialization of a
semaphore structure is done by the sema_init(sem,
count) function. Also notice the if statement that
includes the down_interruptible()
function. Recall that a process put to sleep with this
function can be woken up by a signal. If this is the case,
down_interruptible() returns -EINTR.
We need to test for this condition every time we call
down_interruptible() and return
-EINTR if appropriate. When a process is woken up
by the up() function,
down_interruptible() returns 0.
|
Q9. According to the code fragment shown above, what
happens if the the first process to open the
/dev/mutex device executes the following
instructions:
|
|
Q10. Implement the /dev/mutex driver using
the code fragments introduced above. Show that the
semaphore actually works, by running several processes that
attempt to take the semaphore, delay a few seconds, and
release it. Use ps to verify that the
waiting processes are blocked rather than spinning. |
Conditions
A condition (short for "condition variable") is a synchronization device that allows threads to suspend execution and relinquish the processors until some predicate on shared data is satisfied. The basic operations on conditions are: signal the condition (when the predicate becomes true), and wait for the condition, suspending the thread execution until another thread signals the condition.
A condition variable must always be associated with a mutex, to avoid the race condition where a thread prepares to wait on a condition variable and another thread signals the condition just before the first thread actually waits on it.
A condition variable is defined as
pthread_cond_t.
Some of the functions that operate on conditions are described
below briefly. For more detailed information see the
pthread_cond_wait(3) manual page.
pthread_cond_init(cond, attribute), initialize a condition variable using the attributes in attribute, or default attributes if attribute is NULL.pthread_cond_wait(cond, mutex), automatically unlocks the mutex and waits for the condition variable to be signaled.pthread_cond_signal(cond)restarts one of the threads that are waiting on the condition variable cond.pthread_cond_broadcast(cond)restarts all the threads that are waiting on the condition variable cond.
The example below, taken from the
pthread_cond_wait(3) manual page, shows the use
of conditions in POSIX threads:
pthread_mutex_t mutex;
pthread_cond_t cond;
int x=0, y=0;
int main(void)
{
pthread_t id;
/* initialize condition and its mutex */
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
pthread_create(&id, NULL, &my_thread, NULL);
pthread_mutex_lock(&mutex);
while (x <= y) {
pthread_cond_wait(&cond, &mutex);/* wait for condition */
}
/* so something with x and y ... */
pthread_mutex_unlock(&mutex);
/* keep working... */
pthread_exit(NULL);
}
static void *my_thread(void *p)
{
/* do something ... */
pthread_mutex_lock(&mutex);
/* modify x and y */
if (x > y)
pthread_cond_broadcast(&cond); /* signal condition */
pthread_mutex_unlock(&mutex);
/* do something else... */
pthread_exit(NULL);
}
Wait queues
A wait queue is a linked list of sleeping processes waiting for a certain condition to become true. When the condition is satisfied, the processes on the queue are woken up all at once. This differs from the behaviour of semaphores, in which only one process is woken up when a lock is released. Semaphores are implemented using a special type of wait queue called exclusive wait queue.
A wait queue is identified by a
wait_queue_head_t element, defined in
/include/linux/wait.h, line
77:
struct __wait_queue_head {
wq_lock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
The task_list field points to a list of tasks
waiting on the queue. lock is used to carry out
atomic operations on the task list.
Each element in the wait queue has type
wait_queue_t:
struct __wait_queue {
unsigned int flags;
struct task_struct * task;
struct list_head task_list;
};
typedef struct __wait_queue wait_queue_t;
The functions that operate on wait queues are the following:
sleep_on(queue) and
interruptible_sleep_on(queue), put the
current process to sleep in a wait queue. As with semaphores,
a process put to sleep with the
interruptible function can be woken up by signals. The
implementation of sleep_on() is shown below:
void sleep_on(wait_queue_head_t *queue)
{
wait_queue_t wait; /* entry in the sleeping queue */
init_waitqueue_entry(&wait, current);
wq_write_lock_irqsave(&queue->lock, flags);
__add_wait_queue(queue, &wait)
wq_write_unlock(&queue->lock);
current->state = TASK_UNINTERRUPTIBLE;
schedule();
wq_write_lock_irq(&queue->lock);
__remove_wait_queue(queue, &wait);
wq_write_unlock_irqrestore(&queue->lock, flags);
}
sleep_on_interruptible() is identical to
sleep_on() except for the
TASK_INTERRUPTIBLE symbol instead than
TASK_UNINTERRUPTIBLE.
The function works by inserting a entry (wait) in
the wait queue. The entry is initialized with the
init_waitqueue_entry() function and then added to
the queue using __add_wait_queue(). Next, the
state of the current taks is changed to
TASK_UNINTERRUPTIBLE (for sleep_on) or
TASK_INTERRUPTIBLE (for
sleep_on_interruptible). Finally, the scheduler
function is called, which runs another process in the
runqueue.
To wake up the processes in a specific wating queue, the
kernel provides the following functions:
wake_up(), to wake up all of the
processes in a wait queue, and
wake_up_interruptible(), to wake up only
the interruptible processes.
A simplified version of wake_up() is shown below:
void wake_up(wait_queue_head_t *queue)
{
struct list_head *tmp;
struct task_struct *p;
list_for_each(tmp, &queue->task_list) {
unsigned int state;
wait_queue_t *curr = list_entry(tmp, wait_queue_t, task_list); /* current entry */
tsk = curr->task;
if (tsk->state & (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)) {
tsk->state = TASK_RUNNING; /* wake up task */
if (task_on_runqueue(tsk))
continue; /* task already on the runqueue */
add_to_runqueue(tsk);
reschedule_idle(tsk);
}
}
}
The function wakes up every process in the wait queue. The
process being woken up is added to the runqueue and its state
set to
TASK_RUNNING. reschedule_idle() then
tries to run the process immediately on a CPU that is
currently idle. If no CPU is idle, the function attempts to
preempt a currently running process that has lower priority.
|
Q12. What small change would you make to
wake_up() in order to implement
wake_up_interruptible()? |
In the code below we show a fragment of a device driver that
uses wait queues. The driver has an internal buffer of
BUFMAX bytes of maximum capacity. The current
number of bytes stored in the buffer is given by
buffer_size. A process reads from the driver's
buffer by issuing a read() file
operation. However, if the buffer is empty
(buffer_size==0), the process goes to sleep until
another process writes to the buffer.
static wait_queue_head_t wq; /* the readers wait queue */
static int __init dev_init(void)
{
...
init_waitqueue_head(&wq); /* initialize wait queue */
...
}
static ssize_t dev_read(struct file *filp, char *buf, size_t count, loff_t *offp)
{
if (buffer_size == 0) {
interruptible_sleep_on(&wq); /* go to sleep, wait for writers */
if (signal_pending(current)) /* woken up by a signal? */
return(-EINTR);
}
/* send message to reader */
count = (count>buffer_size) ? buffer_size : count;
copy_to_user(buf, dev_buffer, count);
return(count);
} /* dev_read() */
static ssize_t dev_write(struct file *filp, const char *buf, size_t count, loff_t *offp)
{
/* store message in device buffer */
count = (count>BUFMAX) ? BUFMAX : count;
copy_from_user(dev_buffer, buf, count);
buffer_size = count;
wake_up_interruptible(&wq); /* wake up readers */
return(count);
}
Two things need to be noticed from the code above:
- We always need to initialize the wait queue before we can start using it.
-
Differently from
down_interruptible(), the functioninterruptible_sleep_on()does not return a particular error code when the process is woken up by a signal. Therefore, we need to manually check wether a process was woken up by a signal or by one of the wake-up functions.
|
Q13. Implement the driver described in this section using the code fragment shown above. |
|
Q14. One problem with the code above is that a writer
could change the buffer contents and size while one or
more processes and reading from the buffer. Modify your
code from the previous question so that it prevents
writing to the buffer while a process is reading from
it. Use the semaphore functions
down_interruptible() and up()
as explained in the Semaphores
section. |
|
Q15. Implement a device driver that operates as following.
The driver creates a device /dev/mbox. Only
one process can read from this device, but many processes
can write to it. The device allows messages to be
transferred from the writers to the reader. The reader
should sleep when no messages are available. The writers
should sleep only if a message from a previous writer is
still pending for retrieval by the reader. |
Resources
 |
Web Guide to POSIX Threads |
|
Posix Threads Programming, Lawrence Livermore National Laboratory |